Вот перевод статьи на польский, адаптированный для блога на WordPress:
Uruchomienie pełnego modelu DeepSeek-R1 na komputerze lokalnym
Niedawno natknąłem się na ciekawy wątek w ex-Twitterze (zobacz tutaj), który opisuje, jak uruchomić najpotężniejszy obecnie model AI do rozumowania — DeepSeek-R1 — na własnym komputerze.
DeepSeek-R1 to jedna z najlepszych chińskich modeli językowych, która zyskała ogromną popularność. Została zaprojektowana do zadań wymagających logiki, matematyki i programowania. Model ten jest na tyle zaawansowany, że może konkurować z rozwiązaniami OpenAI, a jednocześnie można go uruchomić lokalnie, bez internetu i bez przesyłania danych do chmury.
Dlaczego warto uruchomić DeepSeek-R1 lokalnie?
✅ Pełna kontrola nad danymi – wszystkie zapytania pozostają na Twoim komputerze, nikt inny nie ma do nich dostępu.
✅ Brak opłat za chmurę – nie musisz płacić za korzystanie z zewnętrznych serwerów AI.
✅ Wysoka wydajność – model rozwiązuje skomplikowane zadania na poziomie eksperckim.
W tym artykule opiszę:
? Jakie wymagania sprzętowe musi spełniać komputer?
? Czym różni się lokalne uruchomienie od pracy w chmurze?
? Jak skonfigurować DeepSeek-R1 i zachować bezpieczeństwo?
? Jakie wymagania sprzętowe ma DeepSeek-R1?
Aby uruchomić DeepSeek-R1 z kwantyzacją Q8, potrzebujesz sprzętu zoptymalizowanego pod kątem pamięci RAM, przepustowości oraz mocy obliczeniowej. Całkowity koszt takiej konfiguracji wynosi około $6,000.
1. Płyta główna
Model: Gigabyte MZ73-LM0 lub MZ73-LM1
? Obsługuje dwa procesory AMD EPYC i 24 kanały pamięci DDR5.

2. Procesor (CPU)
Model: 2× AMD EPYC 9004 lub 9005 (np. EPYC 9115 lub 9015).
? Do inferencji modeli AI kluczowa jest przepustowość pamięci, a nie surowa moc obliczeniowa.
3. Pamięć RAM
? 768 GB DDR5 RDIMM – wymagana do przetwarzania modeli AI o rozmiarze 650 GB.
Przykłady modułów:
✔️ Nemix 384GB DDR5 RDIMM Kit
✔️ v-color DDR5 ECC RDIMM 32GB
4. Obudowa
Model: Enthoo Pro 2 Server Edition
? Przystosowana do płyt serwerowych i zapewniająca odpowiednie chłodzenie.
5. Zasilacz (PSU)
Model: Corsair HX1000i (1000W, modularny).
? Zapewnia odpowiednią moc dla dwóch procesorów i pamięci RAM.
6. Chłodzenie
Model: AMD SP5 CPU Heat Sink 4U H13SSL
? Opcjonalnie: Cichsze wentylatory Noctua NF-A12x25 PWM.
7. Dysk SSD
? 1 TB NVMe SSD – szybki odczyt niezbędny do ładowania modelu.
? Instalacja i konfiguracja oprogramowania
Po złożeniu sprzętu trzeba skonfigurować środowisko AI.
1. Instalacja llama.cpp
llama.cpp to framework do uruchamiania modeli LLM lokalnie.
? Repozytorium GitHub
2. Pobranie modelu DeepSeek-R1
? Rozmiar: 650 GB (Q8 kwantyzacja)
? Źródło: Hugging Face
? Pobierz wszystkie pliki z folderu Q8_0.
? DeepSeek-R1 GGUF Model Files
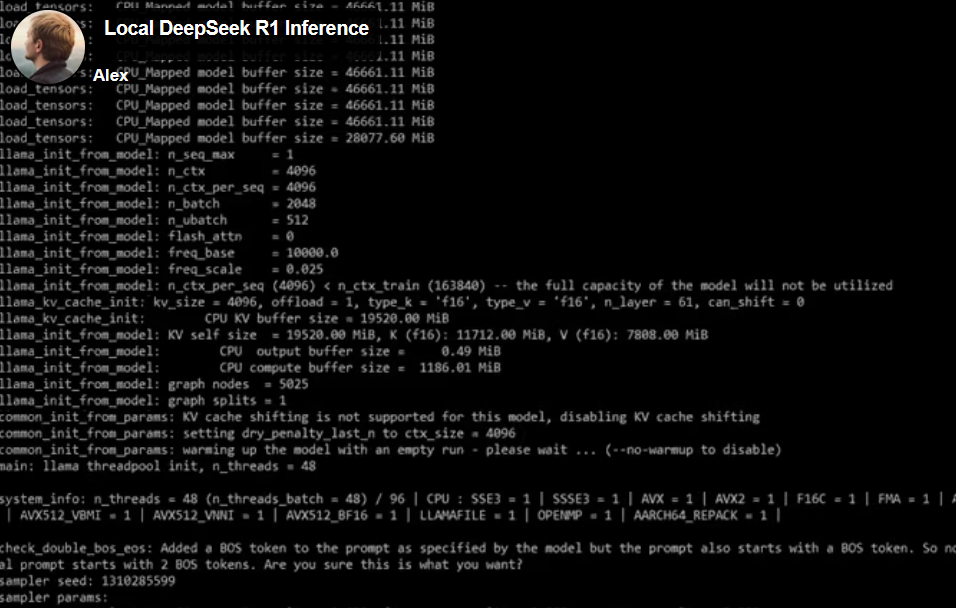
3. Uruchomienie modelu
Przetestuj model komendą:
llama-cli -m ./DeepSeek-R1.Q8_0-00001-of-00015.gguf --temp 0.6 -no-cnv -c 16384 -p "<|User|>How many Rs are there in strawberry?<|Assistant|>"
✅ Oczekiwany wynik: AI odpowiada w czasie rzeczywistym.
⚡ Wydajność i optymalizacja
? Szybkość generacji: 6–8 tokenów na sekundę.
? Długość kontekstu: Przy 768 GB RAM można osiągnąć 100,000 tokenów.
Czy można przyspieszyć model za pomocą GPU?
Tak, ale…
❌ Pełne uruchomienie wymaga 700 GB VRAM, co kosztuje ~$100,000.
✅ Można jednak przyspieszyć model, ładując część (np. 300 GB) na GPU.
? Czy warto zainwestować w lokalne AI?
Z tą konfiguracją możesz uruchomić DeepSeek-R1 Q8 lokalnie, bez chmury i bez zależności od OpenAI. Cała moc AI na Twoim komputerze! ?
Masz pytania lub własne doświadczenia? Podziel się w komentarzach! ?